Hej,
Er der nogle, der kan hjælpe med at aflæse nedenstående ud fra vedhæftet billede?
Angiv konsensussekvensen for:
-10 regionen (6 nukleotider).
-35 regionen (5 nukleotider).
På forhånd tak
Hej,
Er der nogle, der kan hjælpe med at aflæse nedenstående ud fra vedhæftet billede?
Angiv konsensussekvensen for:
-10 regionen (6 nukleotider).
-35 regionen (5 nukleotider).
På forhånd tak
Hej!
Du ska starte med att spørge dig selv, hvordan ser konsensussekvensen ud for -10 regionen og -35 regionen i prokaryoter?
Og sen ska du tælle 10 nukleotider og 35 nukleotider upstrøms om +1, dvs transkriptionsstart, for at finde -10 regionen (pribnow box hos prokaryoter) og -35 regionen.
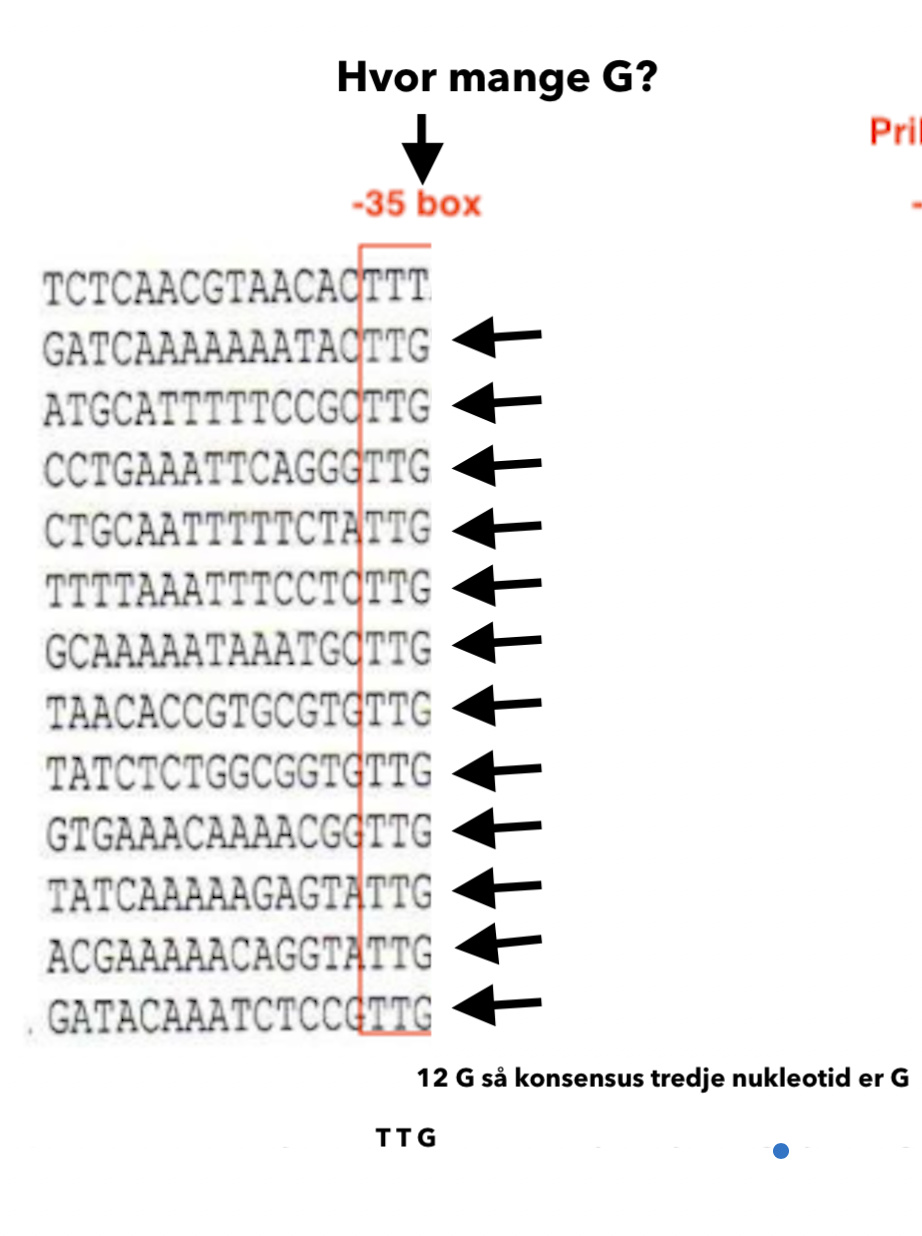
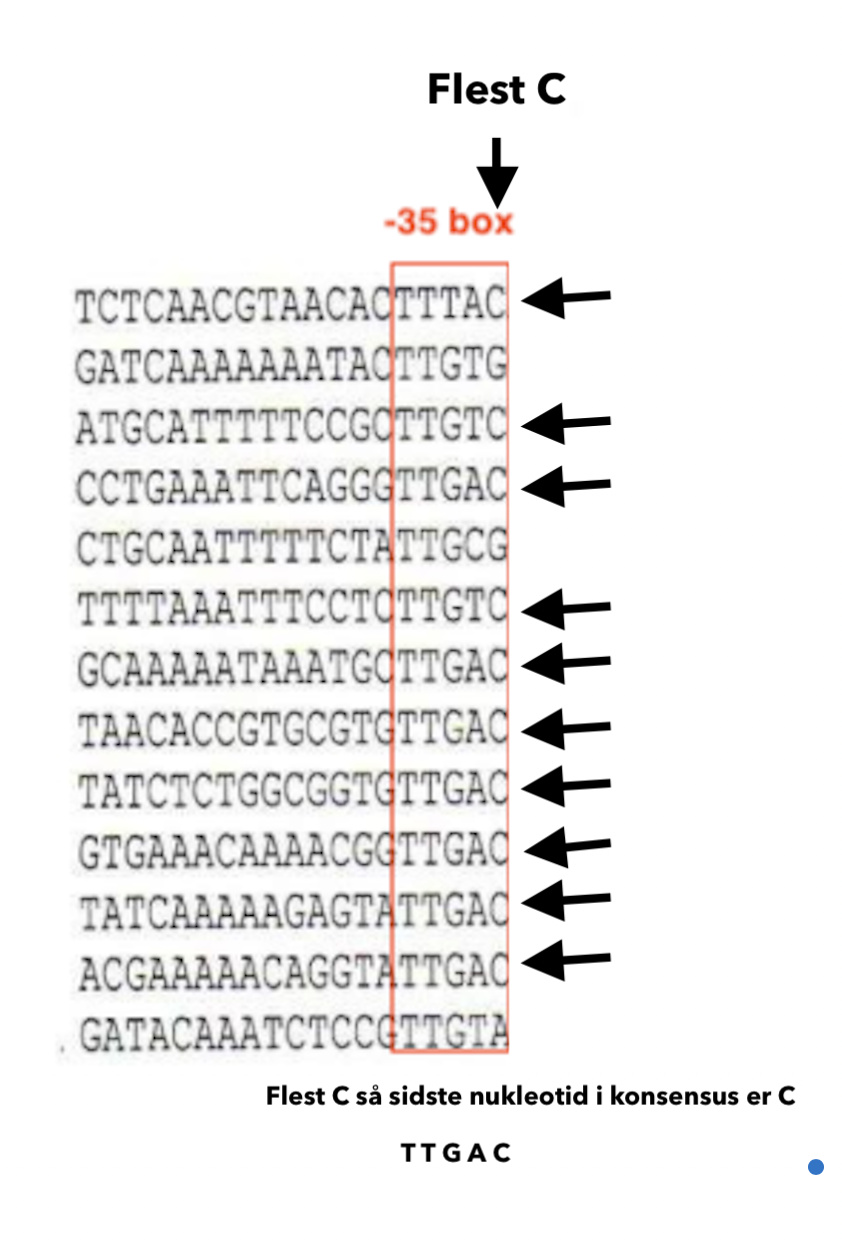
Når du fundet -10 regionen og isoleret de 6 nukleotider så aflæser du hvilken nukleotid som fremgår mest i varje position for alle 13 promotersekvenser (se vedhæftet billede). Fx hvis -10 regionen starter med T i 10/13 promotersekvenser så er den første nukleotid i konsensussekvensen T. Hvis den andre nukleotiden er A i 13/13 promotersekvenser så er den andre nukleotiden i konsensussekvensen A (TA) og så bygger du videre tills du aflæst for alle 6 nukleotider som du isoleret. Du gør detsamme for -35 regionen.
Håbes det giver mening, trots min dårlige dansk 
TUsind tak for din uddybbende forklaring.
Jeg forstår bare stadig ikke hvordan man kan finde u af at -10 og -35 er præcis i den region, som du har indrammet.
Er der en regel, som man kan bruge til at finde ud af det?
Det er en meget god spørgsmål. Den eneste reglen er att disse regioner er højst konserverade fordi de har en viktig funktion i transkriptionen av gener. Så hvis du har flere promotersekvenser, som i tilfældet med denne eksamenspørgsmål, så skal du huske at kigge på alle promotersekvenser efter at du har tællet 10 nukleotider opstrøms for att sikkerstille att du befinner dig i en konserveret region. En god tips er at de to hyppigeste nukleotiden i starten af -10 regionen er 5’-TA så du skal kun kigge opstrøms tills du ser den første TA og sen bliver det nemt at isolere resterande 6 nukleotider.
Ligeledes med -35 regionen, den er højst konserveret. Men det bedste metode, desværre, er at man husker de forskellige konsensussekvenser udenad. Då blir det lettere att aflæse och isolere dem.
Sen er det som regel cirka 17 basparer mellem -10 og -35 boxen, men dette er overkurs.
Mange tak for svar,
Jeg er nogenlunde med på, hvordan man kommer frem til -35 box og -10 box, men hvordan kan jeg præcis aflæse konsensusekvensen for -10 regionen (6 nukleotider) og -35 regionen (5 nukleotider).
Skal jeg aflæse det opstrøms, lodret, vandret?
Derudover forstår jeg ikke hvordan du for konsensus TTGAC på -35 box og TATAAT for -10 box, fx. (hvorfor er det den nederste sekvens du har aflæst)?
På forhånd tak
Du aflæser lodret og ser hvilke nukleotider forekommer mest for hver promotersekvens.
Så forst aflæser du hvilken nukleotid forekommer mest i starten af -35 konsensussekvens.
Sen gør du detsamme for den andre position i de 13 promotersekvenser
Og så videre for den tredje position
Fjerde position
Og sidst femte position
Og så har du fundet konsensus for -35 box. Gør detsamme for -10 box.
Tusind tak - din hjælp er perfekt. Jeg fandt konsensussekvens for -10 og fik det samme som dig 
Jeg sidder og prøver at lave alle opgaver med konsensussekvenser, men hvordan kan man bestemme det på vedhæftet opgave. Jeg ved bare ikke hvilken fremgangsmåde kan jeg bruge her?
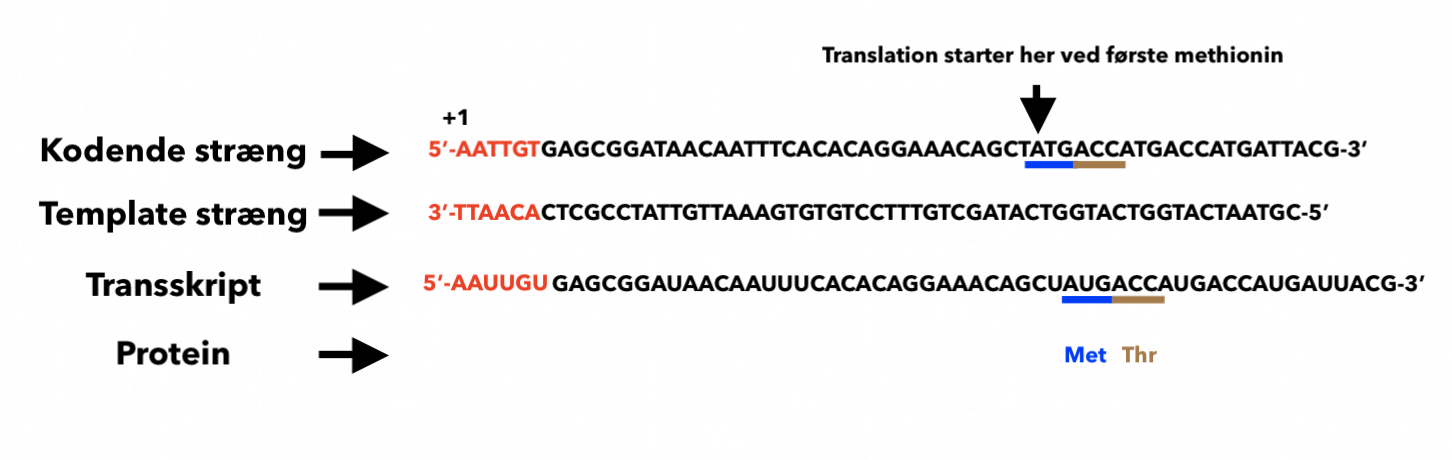
Mit forslag er at jeg skal aflæse de første 6 baser ved +1:
5’-AATTGT-3’
Men da det er mRNA skal den skrives om
5’-UUAACA-3’
De første 2 aminosyrer - her får jeg Leu og Thr, men det passer bare ikke med facit, som er:
Facit:
a. 5’-AAUUGU-3’.
b. Met – Thr (Thr-Met
Min løsning p
Så DNA består af en kodende sträng med orienteringen 5’-3’ og en template stræng med orienteringen 3’-5’. Du presenteres altid med den kodende stræng i opgaver. Det er template strand som faktiskt transkriberes. Så transskript har samme orientering som den kodende stræng dvs 5’-3’ og ser identisk ud med den kodende stræng undtagen at T er erstattet med U.
I vedhæftet figur ser du de første 6 baser i det dannede transskript med rødt. For at løse opgave b så måste du huske at mRNA består af en 5’ untranslated region (5’ UTR). Så du ska kigge downstream tils du finder startkodon for translationen dvs ATG eller AUG hvis du bruger mRNA. ATG/AUG kodar for methionin vilket er altid den første aminosyre i en polypeptid. Jeg har markeret ATG med blå og den andre aminosyra i proteinet med brunt farv.
Mange tak
Men hvordan kan det være at det kun er T der erstattes med U?
Skal man selv skrive template streng og transskript om ud fra den kodende streng?
Og hvis man skal det, hvordan kan man gøre det?
I RNA bruges uracil (U) istedet for tymin (T).
Forstår du hvorfor det røde i figuren ser ud som det gør?
Kodende stræng og template stræng er dubbelstrengs DNA. Når man viser DNA sekvens (som i opgaven) så er det altid kodende stræng som vises (ikke template stræng). Du behøver ikke skrive template stræng hvis spørgsmålet ikke kræver det. Jeg inkluderede det i min besvarelse så at du forstår hvordan DNA transkriberes. RNA polymeras kommer bruge template stræng for at danne en komplementär og antiparallell transkript til template stræng, men samtidigt kommer transkript vara parallell (ha samme orientering) som kodende stræng.
Den eneste forskel mellem kodende stræng og transkript er at transkript har U istedet for T, fordi transkript er “single stranded” RNA (mRNA). Og i RNA så kan ikke T bruges.
Tak
Jeg forstår faktisk ikke hvordan du er kommet frem til det røde eller det efter.
Jeg er med på, at man aflæser ved +1, men det er som om, at du har skrevet sekvensen endnu længere.
Jeg tænker om der en regel for hvordan man skal skrive den kodende streng altså start på +1, men hvornår skal man slutte den kodende streng - fx +50, +70, +100.
Altså du har skrevet den kodende streng fra +1: 5’-AA…CG-3’
Hvordan er du kommet frem til at den kodende streng skal slutte på præcis CG?
Jeg håber at du forstår hvad jeg mener
Haha Clara jeg skrev sekvensen endu længere så at jeg skulle besvare spørgsmål a og b i en og samme figur 
Hele sekvensen i figuren i opgaven
a. Angiv de første 6 baser i det dannede transskript
Her ska man aflæse fra +1 6 baser så:
5’-AATTGT-3’ --> kodende streng i DNA
3’-TTAACA-5’ --> templat streng i DNA
Dvs A danner hydrogen binding med T, T med A, G med C.
Ved transkription kommer disse to streng at separeres (transkription bubble) og mRNA kommer dannes fra templat streng (det er derfor den kaldes templat streng fordi den bruges for at danne transskript):
3’-TTAACA-5’ --> templat streng i DNA
5’-AAUUGU-3’–> mRNA (transskript)
Hvis vi sammenligner transkript med kodende streng så ser vi ligheder:
transskript–> 5’-AAUUGU-3’ og kodende streng i DNA --> 5’-AATTGT-3’.
Hvad er lighederne mellem transskript og kodende streng?
Okay nu giver det meget mere mening  Tusind tak Klaudini!!
Tusind tak Klaudini!!
Hvad er lighederne mellem transskript og kodende streng?
Mit bud er at at både transskript og den kodende streng mindre på mange måder om hinanden. Forskellen er, at T i den kodende streng erstattes med U i transskript
Rigtigt. Så hvis du får en sådan opgave så ska du kun kigge på den kodende streng, aflæse de 6 baser og erstatte T med U og så har du transskriptet
5’-AATTGT-3’ --> 5’-AAUUGU-3’.
Okay og jeg kan genkende denne type opgave ved at der i opgaveformuleringen står “transskript” ik’?
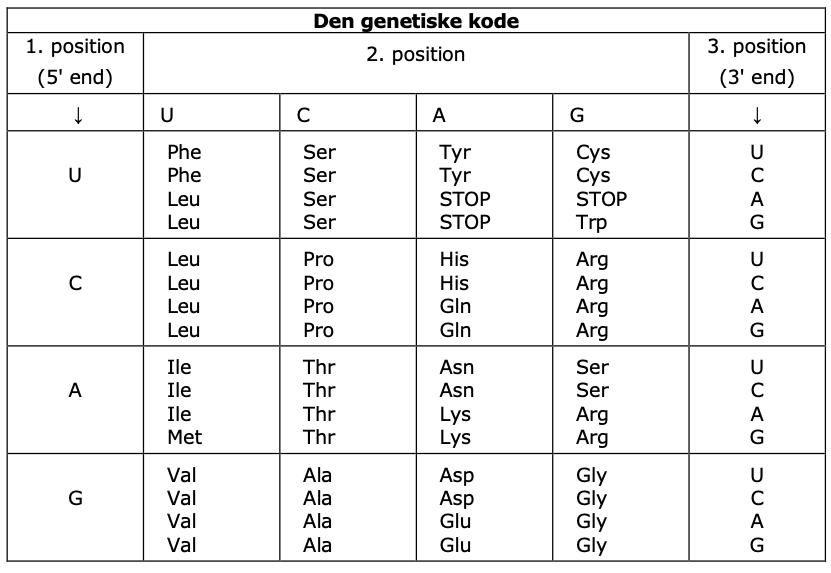
Til eksamen har vi ret til at vedhæftede figur til at bestemme aminosyrer, men når jeg prøver at bruge figuren til at bestemme aminosyrer fx. ud fra AAU eller UGU, så får jeg ikke Met eller Thr, som facit. Har du et bud på hvorfor?
Ja eller så står det pre-mRNA/mRNA.
b. Angiv de første 2 aminosyrer i det dannede protein
Denne opgave kan du lösa genom att kigge downstream om +1 i den kodende streng. Proteiner begynder altid med aminosyren metionin. Kodonet som kodar for metionin er ATG (i kodende streng) eller AUG (i transskript/mRNA).
Så hvis du kigger downstream om +1 hvor er den første ATG belägen?
ATG står ved -10, men hvad med thr?
Fejl riktning du ska till højre ahah downstream betyder till højre.
+40?
Er det altid downstream?
Ja ja. Proteinet dannes altid fra transkriptet.
Ser du figuren ovan? Det er en bild på hele transkriptet fra +1 til poly-A sekvensen. Det gule er den untranslated 5’ ende. Der det står start finns den første start aminosyre (metionin/ATG/AUG kodon) lokalisered. Det grønne område kaldes også open reading frame (ORF) fordi den danner protein. For at besvare din spørgsmål ja, som du også ser i figuren er ORF/det gröna området downstream om + 1.
Jepp i +40 finns ATG. Hvilken kodon finns præcis til højre om ATG?
Brug derefter den genetiske kode for at aflæse de to forste aminosyrer i proteinet.